Uke 14 – Pandas examples¶
Obs
python -m pip install --user pandas
Replace python with the full path on your system. You can find the path with:
import sys
print(sys.executable)
Here we will take brief look at the Pandas library, using the example dataset we have used in the previous chapter.
Pandas is a very useful data analysis library, that makes many common tasks easy to handle. For all the detail, have a look at the introduction here:
https://pandas.pydata.org/docs/getting_started/overview.html
https://pandas.pydata.org/docs/getting_started/intro_tutorials/index.html
Akvakultur¶
Load dataset¶
The data file is the same as before: Akvakulturregisteret.csv.
The instructions on opening files
tell us to use read_csv. The initial attempt
import pandas as pd
akva = pd.read_csv('Akvakulturregisteret.csv')
print(akva.columns)
fails with some errors. We need to tell it about the non-standard delimiter ; and
text encoding iso-8859-1. Also, unusually, the header with column names is in row 1, not 0.
Let’s provide all these as options:
import pandas as pd
import matplotlib.pyplot as plt
akva = pd.read_csv(
'Akvakulturregisteret.csv',
delimiter=';',
encoding='iso-8859-1',
header=1
)
print(akva.columns)
print(akva)
This looks like it works already. Compared to the CSV module, we have much more information
in our pandas dataframe akva. The column names are automatically chosen, and I can print
some information with e.g.:
print(akva['ART'])
print(akva['POSTSTED'].min(), akva['POSTSTED'].max())
Even slicing and filtering works like we’ve seen in numpy:
filter = akva['ART'] == 'Laks'
print(akva[filter])
Plotting¶
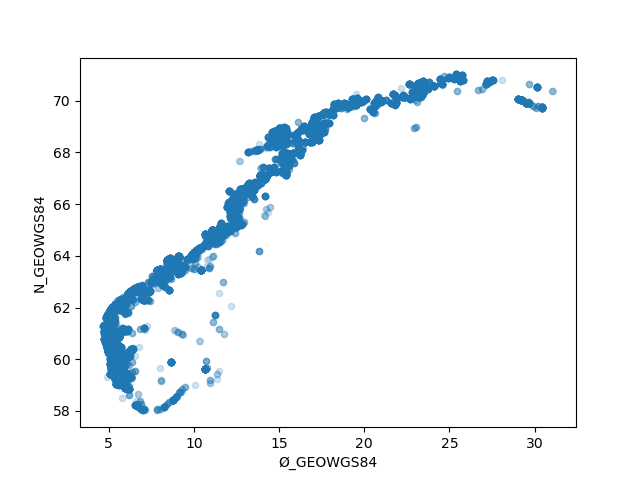
Let’s look at visualization. Again, the beginner tutorial on plotting is very informative. It looks like we only need to add another line, to see a scatterplot of all locations:
import pandas as pd
import matplotlib.pyplot as plt
akva = pd.read_csv(
'Akvakulturregisteret.csv',
delimiter=';',
encoding='iso-8859-1',
header=1,
)
print(akva)
print(akva.columns)
akva.plot.scatter(x='Ø_GEOWGS84', y='N_GEOWGS84', alpha=0.2)
plt.show()
Tasks from CSV chapter¶
The different common data analysis tasks we saw before can be done easily with pandas:
Count the different species (ART, column 12). Googling count categories in pandas suggested
value_counts():print(akva['ART'].value_counts())
Plot only those that grow Laks. Here, we can use filters:
laks = akva[ akva['ART'] == 'Laks' ] laks.plot.scatter(x='Ø_GEOWGS84', y='N_GEOWGS84', alpha=0.2))
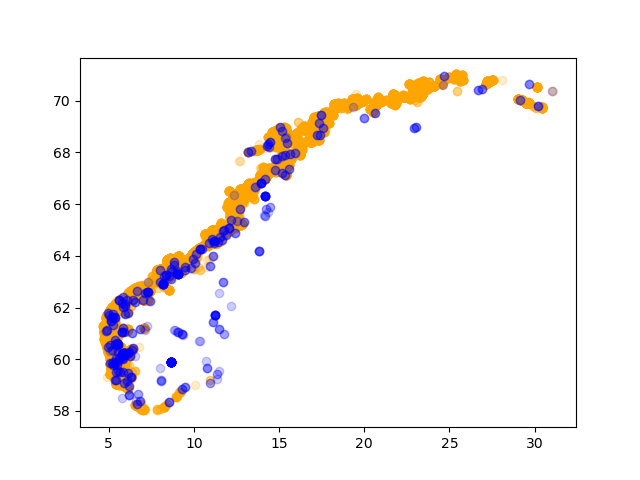
Plot FERSKVANN in one colour and SALTVANN in another (VANNMILJØ, column 20). Again we can use filters. The scatter plots here are the usual matplotlib plots, not the ones from pandas. You can see that the libraries work well with each other:
import pandas as pd import matplotlib.pyplot as plt akva = pd.read_csv( 'Akvakulturregisteret.csv', delimiter=';', encoding='iso-8859-1', header=1, ) salt = akva[ akva['VANNMILJØ'] == 'SALTVANN' ] plt.scatter(x=salt['Ø_GEOWGS84'], y=salt['N_GEOWGS84'], c='orange', alpha=0.2) fersk = akva[ akva['VANNMILJØ'] == 'FERSKVANN' ] plt.scatter(x=fersk['Ø_GEOWGS84'], y=fersk['N_GEOWGS84'], c='blue', alpha=0.2) plt.show()
Weather data¶
This is an example of using pandas and matplotlib to deal with large datasets:
Summary¶
Pandas is one of the most used data analysis tools in science, and offers far more than we can show in the frame of an introductory lecture on Python. If you find it useful, start on the pandas website, and follow through the tutorials with your own data in mind.
Oppgaver¶
Denne ukas oppgaver er ganske store og dere må bruke ting vi har lært fra hele semesteret.
Oppgave 1¶
I denne oppgaven skal vi jobbe med datasettet VIK_sealevel_2000.txt som inneholder målinger
av havnivå for hver time av året 2000.
a) skriv en funksjon
read_datasom tar inn et filnavn og returnerer en pandas dataframe der den første kolonnen (index) skal ha navnetdateog innholderdatetime. De andre kolonnene skal ha navnyear month day hour sealevel. Du kan anta at filen har samme format somVIK_sealevel_2000.txt.Tips: her er det lurt å se på read_csv og to_datetime
Eksempelkjøring for pandas dataframe. Obs! hour må være 0-23, ikke 24!
>>> print(data.head()) year month day hour sealevel date 2000-01-01 00:00:00 2000 1 1 0 335 2000-01-01 01:00:00 2000 1 1 1 336 2000-01-01 02:00:00 2000 1 1 2 338 2000-01-01 03:00:00 2000 1 1 3 341 2000-01-01 04:00:00 2000 1 1 4 347b) skriv en funksjon
plot_monthssom tar inn en dataframe formatert som i a) og plotter en graf som viser gjennomsnittlig havninvå for hver måned. Gi grafen og aksene passende navn, og velg noen fine farger.c) skriv en funksjon
plot_rolling_averagesom tar inn en dataframe formatert som i a). Funksjonen skal plotte havninvået for juni måned både direkte og som et glidende gjennomsnitt (rolling average). Velg periode for det glidende gjennomsnittet selv. Grafen kan f.eks se sånn her ut: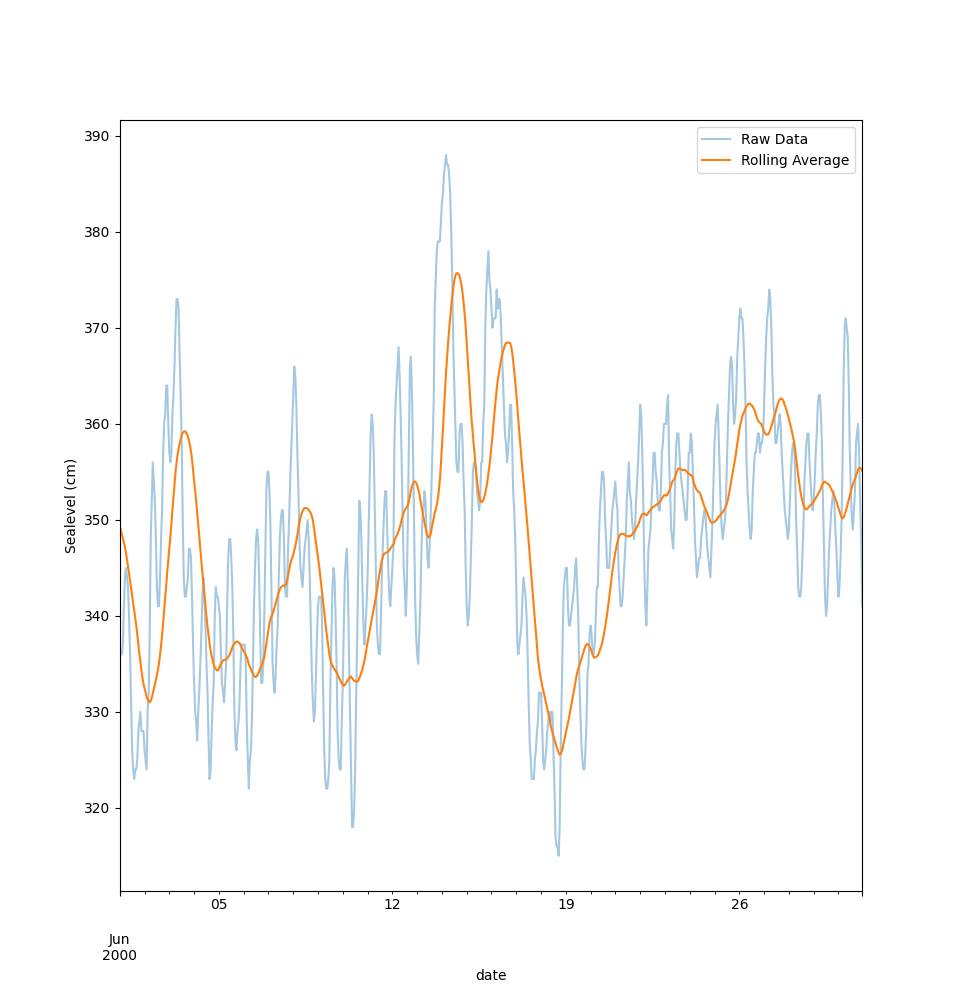
Tips: se på rolling
Oppgave 2¶
Du og naboen din har begge like store hager. Hagene deres representeres som
2D-lister, hvor garden[i][j], gir et element på posisjonen (i, j). Hvert
element i en hage er representert som en streng, og kan være en av de følgende:
"grass", "moss", "strawberry", "rock", "raspberry". Du har i det siste sett
at det har blitt litt vel mye mose og stein i hagen din, og mistenker at det er
naboen din som har lagt det der. For å fikse opp i dette, skal du fullføre
funksjonen clean_garden(my_garden, neighbors_garden). Her skal du først lage
små funksjoner for å gjøre det enklere å løse den faktiske oppgaven.
Til slutt skal du bytte ut hvert stein og mose fra din hage, med den første jordbær og bringebær fra naboen sin hage som finnes (de to ting som skal byttes trenger ikke å være på samme posisjon).
Last ned uke14_oppgave_2.py og fullfør funksjonene:
find_itemsom tar inn to argumenter:(garden, item), som returnerer en(i, j)posisjon som en tuppel, hvisitemfinnes igarden. Hvis det ikke finnes, returnerer duNoneswap_itemssom bytter ut to elementer mellom to hager, la den ta inn disse argumentene:(garden1, garden2, pos1, pos2), hvorpos1ogpos2er(i, j)tupler. Her skal du ikke returnere noe, men endre listene du får inn som argumenter.
Bruk funksjonene du har skrevet til å fullføre
clean_garden(my_garden, neighbors_garden):
Bytt ut all «rock» med «strawberry», og «moss» med «raspberry» fra naboen sin hage
så lenge det finnes muligheter for bytte.
Oppgave 3¶
En vanlig sikkerhetsmetode for banker er å spørre brukeren for tre random nummer fra en passkode. Om passkoden er 531278 og de spør etter 2., 3. og 5. nummer vil det riktige svaret være 317.
Filen keylog.txt inneholder 50 korrekte innloggingsforsøk. Gitt at de tre numrene de spør etter alltid er i rekkefølge,
bruk filen keylog.txt til å finne den korteste mulige passkoden av ukjent lengde.
(Løsningen er 73162890) OBS: Det er ingen automatiske tester for oppgave 3